ProPublica is an independent, nonprofit newsroom that produces investigative journalism. Their team includes more than 100 investigative journalists and even more support staff for online publishing.
ProPublica is a fully online journalism resource. As part of a major website upgrade, all content needed to be migrated and verified. This included thousands of published articles, metadata, categorizations, and workflows.
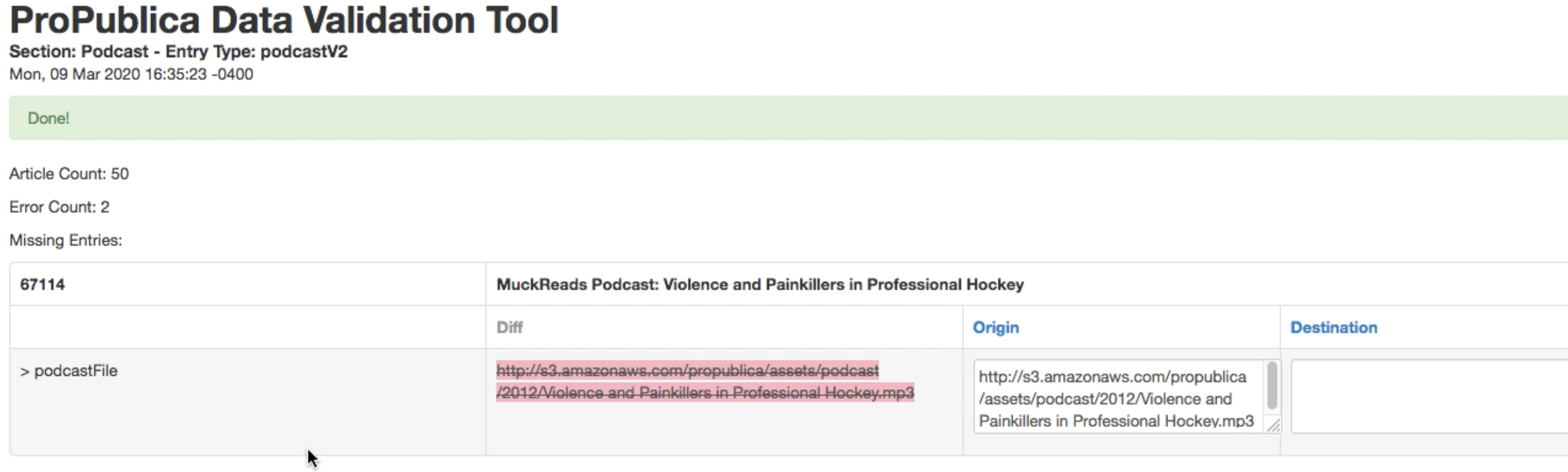
We built a new quasi-AI powered content validation tool that helped one human scale herself up to validate millions of chunks of data.
ProPublica's website consists of more than 30,000 stories. Each story had more than 70 data attributes. More than 2m items of data needed to be verified.
We conceived a custom tool and used it to make sure that the data transfer was reliable and stable up to and even after launch.
We reduced the content validation process down from a months-long process to one that took just minutes.
ProPublica has happily run its website using Craft CMS since shortly after Craft came on the market. Recently Craft 3.x was released and ProPublica wanted to upgrade. The ProPublica publishing team is always working and content is constantly making its way through the system. Taking the site offline for the Craft upgrade was not an option. It would have been too risky and disruptive. So, we opted to migrate all content from the Craft 2 system to the Craft 3 system while keeping the old version live. This bought us a lot of time for development and QA and took the pressure off.
At the time of the content migration, the ProPublica site consisted of more than 30,000 web pages. Each of the content entries representing these pages had upwards of 70 data attributes from text blocks to images to tables and the like. This accounted for more than 2 million nodes of data that needed to be correctly migrated from one system to the next. Every node of the content migration had to be validated to ensure that everything had been brought over correctly. One human or even a group of humans could not manage this scope. We needed some machine help.
Big data problems like this one are great places for machine learning and AI. When we engaged on the project we assumed that a tool already existed which would make it easy for us to compare the two data sets and find issues. It turns out that a tool to "automagically" do all that we wanted didn't exist. As we dove further into things, we realized that what we wanted was not a magical tool to do our work for us. What we needed was a tool that would help us scale our human abilities. We needed a hybrid of human and machine, a cyborg if you will.
Since our CMS was Craft we had access to the highly effective FeedMe plugin. This tool can ingest JSON or XML feeds and create / update content entries in the destination site. To feed FeedMe we created a number of JSON feeds on the origin Craft 2 website. This allowed us to create companion JSON feeds on the destination site and compare the two feeds. All we needed was a tool that could do the comparison work and alert us where issues surfaced. The human operator, using this tool, could then make corrections in the system where appropriate.
When validating so much data we needed to be able to gradually educate the tool. We needed to be able to teach it what to ignore, what to care about, and what to correct for on the fly. We needed our tool to learn and become faster and smarter. We even needed our tool to make changes in data it was validating on the fly so that we would not see false positives for discrepancies in image URLs or other systemic changes that were intentional variations between the two sites.
Knowing all of the above requirements, we tried an initial proof of concept using Javascript on a web page to compare our two data sources. We would point the tool at one of the feeds, just a URL on the web. We would loop through that feed and call the counterpart data source. Our Javascript code then compared the two feeds recursively walking through each data node and verifying that everything matched. We baked the ability to be educated over time into the Javascript code so it could more effectively cycle through the feeds in subsequent cycles.
Virtually all of our client engagements require content stewardship services. This content migration for ProPublica was no exception. Content stewardship is the set of activities involved in keeping up with the care and feeding of website content. It's surprising how degraded web content itself can get over time. Data models change. Publishing standards and priorities change. The capabilities of the web change. Content stewardship involves the human level activity of making sure that website content itself meets an appropriate standard.
Our content validator tool was an essential element in our content stewardship activities for ProPublica. It was indispensable to the team that was accountable for the integrity of the content migrated from the Craft 2 to Craft 3 site.
Thanks to the effectiveness of the validation tool, ProPublica was able to comfortably rely on the integrity of the migrated content. They launched the new site with high confidence that all data had been ported over correctly.
A short chat can surface quick wins and a clear path forward.